
Fuzzy Matching Algorithm
In this post, we are going to explain how to create your fuzzy matching algorithm. We also show the steps needed to develop your version of this algorithm. We also propose solutions for common fuzzy matching challengues.
What is fuzzy matching?
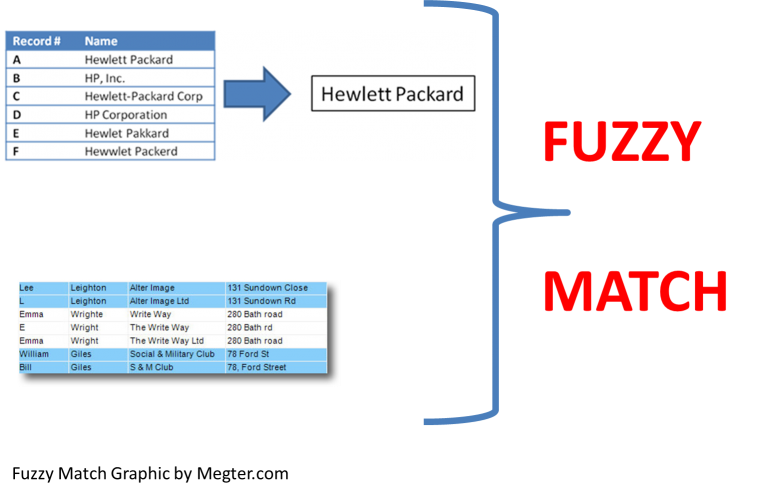
Fuzzy matching (also known as record linkage or entity resolution) is the process of mapping similar entities across different data sources. The word entities may refer to a table in a database, a text string, or a group of attributes.
In the following table, we described the type of matches between two data sets:
- Exact.- The two entities are the same (for example, Microsoft Corporation -> Microsoft Corporation).
- Similar.- The two entities are the same after the preprocessing process (for example, Microsoft -> Microsoft Corporation).
- Fuzzy.- The matching between two entities is not 100% exact (for example, Microsft -> Microsoft Corporation).
Fuzzy matching is a matching learning problem because we can optimize the parameters involved in the algorithm. Usually, the algorithm uses heuristics and external data sources to find matches between two data sources.
Types of fuzzy matching algorithms

Fuzzy matching algorithms can be classified by type of scope or by the number of attributes.
The type of scope refers to whether the algorithm can englobe all industries or a specif industry. For example, matchkraft focuses only on matching company names. However, there are general fuzzy matching services that encompass many areas (person names, product names, etc.).
Regarding the number of attributes, there are single or multi-attributes matching algorithms. For example, if there is only one text attribute the fuzzy matching process is known as fuzzy string matching. On the contrary, when multiple attributes are involved, fuzzy logic (or crisp logic) is needed to match the records.
In this post, the general fuzzy string matching algorithm is going to be analyzed.
Fuzzy Matching Algorithm Description
This section is going to show the general idea of the algorithm. Let’s start by defining the input data and the industry.
For example, we have the following array of product names:
- Jordan Sneakers Running Men
- Amazon Brand – 206 Collective Men’s Mark Sneaker
- Adidas Men’s Questar Flow Sneaker Running Shoe
- Skechers Sport Women’s Energy Sneaker
- New Balance Women’s FuelCore Nergize Sport V1 Sneaker
The second array of product names is the following:
- New Balance Women’s FuelCore Nergize V1 Sneaker
- PUMA Men’s Roma Basic Sneaker
- Roxy Women’s Bayshore Slip On Shoe
- Jordan Mens Air 12 Retro Dark Concord
- Jordan Men’s Shoes Nike Air 1 Mid Chicago
As we can see a simple vlookup in Excel is not going to match the two data sets. Let’s start explaining the algorithm for matching the two-string arrays.
Step 1 (Remove Duplicates)
The first step removes duplicated names or empty strings.
Step 2 (Preprocessing)
The second step involves preprocessing the data. Here, we have to apply text mining techniques such as: stemming, lemmatization, stop words removal, trimming, remove accents, remove all non-alphanumeric characters, replace multi spaces, remove duplicates words from a record, number to string transformation, uppercase transformation, and special characters replacements.
Let’s preprocess the following string: Amazon Brand – 206 Collective Men’s Mark Sneaker
- Remove all non-alphanumeric characters = Amazon Brand 206 Collective Mens Mark Sneaker
- Stemming and lemmatization = Amazon Brand 206 Collect Men Mark Sneaker
- Stopwords removal = 206 Collect Men Mark
- Number to string transformation = two hundred six Collect Men Mark
- Uppercase transformation = TWO HUNDRED SIX COLLECT MEN MARK
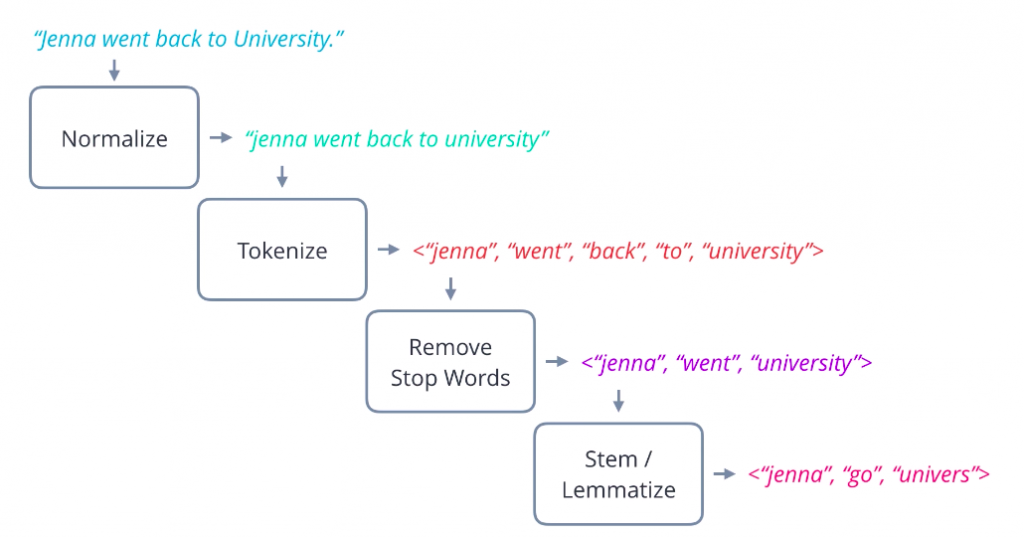
Step 3 (Matching Process)
The string matching occurs after performing the preprocessing step. The matching process typically involves a distance function. The distance function tells us the level of similarity between two strings. Usually, the distance is display as a number from 0 to 100. However, the output depends on the type of distance function.
The two most common distance functions are the Levenshtein and the Jaro-Winkler distance. You can find both implementations on several open-source projects, such as the FuzzyWuzzy package.
In our example, we have to compute 25 (5*5) pairwise distances. If the distance value goes beyond a certain threshold, we can assume the two strings are the same. Finding the best distance measure and the best threshold is part of another algorithm called model optimization. A common threshold is 85% of similarity between two strings.
In our example, we can compare the Levenshtein distance of the product: Jordan Sneakers Running Men from the first string array. And Jordan Men’s Air 12 Retro Dark Concord from the second array. Remember to preprocess the data.
Levenshtein distance (JORDAN RUN MEN, JORDAN MEN AIR TWELVE RETRO DARK CONCORD) = 28% similarity
Now, let’s check the similarity with other product names.
Levenshtein distance(NEW BALANCE WOMEN FUELCORE NERGIZE SPORT V1, NEW BALANCE WOMEN FUELCORE NERGIZE V1) = 87% similarity.
How to deal with big data sets?
Let’s imagine that we want to match two data sets with 100 records each. Then, we need to perform 100 * 100 =10,000 comparisons. If we increase the size of data sets, the search requires more time because the number of comparisons increases exponentially. The way to solve this problem is called blocking (also known as partitioning).The blocking process aims to narrow down the number of comparisons of the fuzzy matching process. For example, in the following paper called A Study on Company Name Matching for Database Integration, researchers use country codes not to compare companies from different countries.
Another well-known strategy to reduce the amount of time is to use an inverted index to retrieve similar names. Lucene or Elasticsearch are popular libraries to create inverted indexes and perform text retrieval.
Applying parallelism can reduce the execution time even further. For example, the blocking and inverted index processes can be easily executed in parallel across different cores.

Conclusion
In this post, we explain a basic fuzzy matching algorithm. We also talk about the difficulties that we can face during the development of this type of algorithms. Besides, we didn’t expose all the technical details because we aim to show the inherent complexity behind a fuzzy matching algorithm. However, it is the inner complexity that makes the fuzzy matching process an exciting problem to solve.
One topic that we didn’t cover in this post is how to manage fuzzy matching with multiple attributes. As we said before, multiple attributes need a fuzzy controller to decide when a record belongs to an entity and when not. Another topic that was out of scope was model optimization. Model optimization usually involves a training set and a testing set.
In MatchKraft, we are constantly improving our fuzzy matching algorithm for company names.